Summary: トリプルストア及びグラフデータベースに関する技術調査¶
背景¶
近年、RDF関連のソフトウェア開発が進展し、世界中で様々なRDFストア(トリプルストアと呼ばれる)が公開されてきた。よく用いられている実装の一例としてはOpenLink Software Virtuosoがあるが、その他にも多くの新しい実装が活発に開発されてきており、多くの実装について、性質や性能が自明ではない。また、グラフを基礎としたデータモデルを採用しているデータベースとしては、プロパティ・グラフモデルに基づくデータベース実装も出てきており、近年より活発に開発が行われている。トリプルストアに加えて、プロパティ・グラフモデルに基づくデータベース実装に言及するとき、グラフデータベースと呼ばれることが多い。
このように活発に開発が続けられているトリプルストア及びグラフデータベースの分野は、進展が早くまた製品も多様性に富むため、現状を把握するのは容易ではないが、各データベースの有用性を評価するために、標準準拠状況、性能の観点から継続的に調査を行うことが望ましい。こうした評価情報は、RDF等の基盤技術を利用している研究機関において共有されるべき重要な情報である。
トリプルストアの各実装¶
Virtuoso¶
Virtuosoは、OpenLink Software社の開発するデータベースエンジンである。Open-source版とcommercial版がある。本調査では、open-source版を用いている。RDBMSを基盤としているが、RDFも扱えるようになっている。もともとrow-wiseであったが、Virtuoso 7からはcolumn-wiseを用いるように拡張された。graph identifier gと、(s, p, o) からなる4つ組(quads)をストアする。インデックスは、<g, s, p, o>と<o, g, p, s>である。
多くのRDFワークロードでは、削除が少なく、大量の読み込みを必要とするため、デフォルトのインデックススキームは、これらに最適化されている。このような状況で、この方式はスペースを大幅に節約し、より良い作業セットを実現する。通常、このレイアウトは、4つのフルインデックスを使用したレイアウトの60~70%のスペースで済む。これが現実的ではない場合、インデックススキームはフルインデックスのみを持つべきである。つまり、各キーがクワッドの主キーのすべての列を保持する。これは、CREATE INDEX文でDISTINCT NO PRIMARY KEY REFオプションが指定されていない場合に当てはまる。このような場合、削除されてもすべてのインデックスは厳密に同期される。
http://docs.openlinksw.com/virtuoso/rdfperfrdfscheme/
https://www.amazon.co.jp/RDF-Database-Systems-Triples-Processing/dp/0127999574
ウェブサイト
http://vos.openlinksw.com/owiki/wiki/VOS
バージョン
7.2.5.1 (2018/08/15)
ライセンス
GPLv2
その他必要条件
automake, libtool, gperf パッケージをaptでインストールする必要がある。
Installation¶
ソースを取得
git clone git@github.com:openlink/virtuoso-opensource.git
cd virtuoso-opensource
git checkout v7.2.5.1
コンパイル
./autogen.sh
./configure --prefix=/path/to/install/directory --with-readline
make
make install
ポート1111を既に使用していると、makeの途中で失敗する。(テストに1111を使おうとするため)
configure に --with-port=1112 オプションを付けるなどすれば失敗を回避できるかもしれないが、1111を空けておくのが確実。
起動
cd /path/to/install/directory/var/lib/virtuoso/db/
/path/to/install/directory/bin/virtuoso-t +wait
http://localhost:8890/sparql でSPARQLエンドポイントが起動していることを確認する。
データの取得
curl -LOR http://example.com/example.ttl
ロード
isql 1111 dba dba
SQL> DB.DBA.TTLP_MT(file_to_string_output('example.ttl'), '', 'http://example.com/example.ttl', 0);
Configuration¶
デフォルトから設定を変更したい場合
- 設定ファイルの編集
vi /path/to/install/directory/var/lib/virtuoso/db/virtuoso.ini
問い合わせによって、virtuoso-temp.dbのサイズが肥大化していくことがある。その場合、virtuoso.iniの中でTempAllocationPct(virtuoso.dbに対して、何%まで許容するか)を設定する。参照
TempAllocationPct = 100
Troubleshooting¶
./configure で OpenSSLに関するエラーが出ることがある。この場合は、libssl1.0-dev をインストールする。
sudo apt install -y libssl1.0-dev
Ubuntu 20.04 LTSでは、パッケージ libssl1.0-dev が見つからないことがある。この場合は、/etc/apt/sources.list の末尾に以下を追加して apt update を行う。
deb http://security.ubuntu.com/ubuntu bionic-security main
sudo apt update
sudo apt install -y libssl1.0-dev
GraphDB¶
GraphDBは、Ontotext社の開発したトリプルストアであり、ライセンスとしてはFree版とStandard版、Enterprise版が存在する。実装言語はJavaのため、JVMの動作する基板上であれば使用可能である。
GraphDB Free Edition 9.3.1 (https://www.ontotext.com/products/graphdb/graphdb-free/) に関して、弊社内Linuxサーバへのインストールを行い、インストール、Webサーバの起動、GUIへのアクセス方法、SPARQLクエリを発行する方法をGitHub内のdocs/md/graphdb.mdに記載しました。また、貴研究所より指定されたデータセットに関して、GraphDBでロードした場合に要する時間の調査を行い、環境情報とともにスプレッドシートに記載しました。
ウェブサイト
https://www.ontotext.com/products/graphdb/
更新履歴
http://graphdb.ontotext.com/documentation/free/release-notes.html
本記事の対象バージョン
9.3.1 (2020/06/18リリース)
ライセンス
無料版が存在するが、同時に発行できるクエリは2つまでとの記述有り。有料ライセンスはStandard版とEnterprice版の二種
Installation¶
- GrahDBのフリーエディションを使用するため、サイト上でユーザ登録をする https://www.ontotext.com/products/graphdb/graphdb-free/
- ユーザ登録が完了すると、登録したメールアドレスにインストール用バイナリのダウンロード用リンクが送られてくる
- Download as a stand-alone serverのリンクをクリックしてダウンロード(Desktop installationではない方)
- ダウンロード後、zipを解凍してそのフォルダへ移動
$ cd path/to/unzipped/folder
- GraphDBをワークベンチモードで起動
$ sudo ./bin/graphdb
- ブラウザで localhost:7200 にアクセスすると、GraphDBのホーム画面が表示される
- 新しいリポジトリを作るため、左のメニューから、Setup->Repositories->Create new repositoryと選択する
- リポジトリのIDを入力し、最下部のCreateをクリック
- ターミナル上で、以下のコマンドを実行して ttl データをインポート
- なお、loadrdfコマンドではインポートするグラフに名前をつけることができない模様。
- このため、グラフ名をつける必要がある場合はブラウザ上のhttp://localhost:7200/import から行う必要あり?
$ sudo ./bin/loadrdf -f -i <repository_name> -m parallel <path to dataset>
- インポートが完了したら、ブラウザに戻り左のメニューからSPARQLをクリックする
- リポジトリのリストが表示されるのでリポジトリを選択する
- SPARQLのエディタが表示されるのでSPARQLを入力後、RUNで実行できる
- APIからSPARQLを実行したい場合は、http://localhost:7200/repositories/<リポジトリ名> にGETリクエストを送ればよい
Stardog¶
Stardog 7.3.2 (https://www.stardog.com/get-started/)に関して、弊社内Linuxサーバへのインストールを行い、インストール方法をdocs/md/stardog.mdに記載しました。
Linuxサーバへインストールを行ったStardog 7.3.2に関して、データのロード時間を計測いたしました。
ウェブサイト
Getting Started
https://www.stardog.com/docs/#_setting_path
本記事の対象バージョン
7.3.2(2020/07/01リリース)
ライセンス
完全にフリーなライセンスは存在しないが、30日分の体験版、1年のアカデミックライセンスの体験版がある。
Installation¶
Stardogの最新版をダウンロードして解凍して移動
wget https://downloads.stardog.com/stardog/stardog-latest.zip
unzip stardog-latest.zip
cd stardog
Stardogのサーバを起動。
./bin/stardog-admin server start
- 初回起動時にはライセンスに関する質問をされるので、利用規約への同意やメールアドレス、Stardogから送られる情報をメールで受け取りたいかなどを聞かれるので、答える。
- この時点で5820番ポートでサーバが起動するが、このままの状態ではWebブラウザからアクセスしても何も表示されない。
- GUIが必要な場合は、別途Stardog Studioをインストールする必要があるらしい https://www.stardog.com/studio/
- なおデフォルトのユーザ名/パスワードはadmin/admin
- コマンドライン上でクエリを実行できればいい場合は、以下を参照のこと。
- データをロードしてDBを作るため、以下のようなコマンドを使用する。
./bin/stardog-admin db create -n myDB /path/to/some/data.ttl
- 名前付きグラフにロードしたい場合は、入力するRDFファイルの名前の前に@<グラフのURL>のようにする。以下はhttp://examples.org の例
./bin/stardog-admin db create -n myDB @http://examples.org /path/to/some/data.ttl
- クエリはコマンドライン上から以下のように実行できる
./bin/stardog query myDB "SELECT DISTINCT ?s WHERE { ?s ?p ?o } LIMIT 10"
- Web API越しにSPARQLを実行したい場合は http://localhost:5820/<DB名>/query に対してGETリクエストを送る
AllegroGraph¶
AllegroGraph はFranz社の開発したマルチモデルデータベースであり、ドキュメントデータとトリプルデータの両方をサポートしている。ライセンスとしてはFree,Developer, Enterpriseの三種類が存在する。実装言語はJava, Python, Common Lispである。
AllegroGraph Free Edition の7.0.0(https://franz.com/agraph/downloads/)に関して、弊社内Linuxサーバへのインストールを行い、インストール方法、データセットのロード方法、クエリの発行方法をdocs/md/allegrograph.mdに記載しました。
6月に弊社Linuxサーバへインストールを行ったAllegroGraph 7.0.0 に関して、データのロード時間を計測いたしました。ただし、フリー版のライセンスでは500万トリプル以上のデータをロードすることができず、対象データ全体を扱えなかったため、参考情報として行数を先頭から500万行分に限定したファイルを使用してロード時間を計測させていただきました。
貴研究所担当者様より頂いたAllegroGraph Enterprise Editionのライセンスを利用し、弊社でEnterprise Editionを用いたロード時間の測定を行いました。この際、AllegroGraph開発者より入力ファイルの形式がturtleファイルかntriplesファイルかでデータのロードの並列性能に差があるという連絡を受けたため、入力ファイルをturtleからntriplesに変換したものも用意し、ntriplesでのみ並列化の効果があることを確認しました。
ウェブサイト
https://allegrograph.com/products/allegrograph/
Quick Start
https://franz.com/agraph/support/documentation/current/agraph-quick-start.html
本記事の対象バージョン
7.0.0
ライセンス
Free, Developer, Enterpriseの3形態あり。Free だと 5000,000 トリプルと3サーバまでの制限あり(https://allegrograph.com/allegrograph-editions/)
Installation¶
- 以下のURLに名前とメールアドレスを入力して、tarファイルをダウンロード
https://franz.com/franz/agraph/ftp/pri/acl/ag/ag7.0.0/linuxamd64.64/agraph-7.0.0-linuxamd64.64.tar.gz.lhtml?l=agfree
- tar ファイルを解凍後、解凍したフォルダに移動し、インストールしたいディレクトリを指定してインストール
cd agraph-7.0.0
sudo ./install-agraph /path/to/install/directory
- インストールの際、いくつか質問されるので答えていく。ユーザ名とパスワード以外はデフォルトで良さそう。
- ユーザ名とパスワードに関しては、後でデータセットをロードする時に必要になる。
- ユーザはデフォルトだとagraphになるが、シェルのユーザ名と同じにしておくと良い。
- インストールしたディレクトリに移動後、以下のコマンドでサーバを起動
sudo ./bin/agraph-control --config ./lib/agraph.cfg start
- ブラウザで、
http://127.0.0.1:10035にアクセスする。 - ユーザ名とパスワードを入力して、サインインする。
- リポジトリを好きな名前で作成する。
- コマンドラインに戻り、以下のコマンドでロードを行う。
repository_nameとpath/to/datasetは適宜読み替える。(ブラウザ上のimport RDFからロードすることも可能)
./bin/agtool load repository_name path/to/dataset
- グラフ名を指定したい場合は、 -g オプションを使用する
./bin/agtool load repository_name -g http://example.org path/to/dataset
- ロード完了後、ブラウザ上でqueries のタブを選択し、クエリを入力して実行する。
- Web APIからSPARQLを実行したい場合は、 http://localhost:10035/repositories/<リポジトリ名> に対してPOSTで実行する(queryパラメータにクエリの内容を含める)。GETで送るとエラーになるので注意。
- 実行中のサーバを止めたい場合は、以下のコマンドを実行する。
sudo ./bin/agraph-control --config ./lib/agraph.cfg stop
Blazegraph¶
BlazegraphはSYSTAP社が開発したオープンソースのトリプルストアであり、WikidataのSPARQLエンドポイントとして採用されている。実装言語はJavaであり、SPARQLに加えてGremlin APIもサポートしている。
BlazeGraph 2.1.6に関して、弊社内Linuxサーバへのインストールを行い、インストール方法、データセットのロード方法、クエリの発行方法をdocs/md/blazegraph.mdに記載しました。また、データのロード時間の計測を行いました。
BlazeGraph 2.1.6に関して、弊社内Linuxサーバへのインストールを行い、インストール方法、データセットのロード方法、クエリの発行方法をdocs/md/blazegraph.mdに記載しました。また、データのロード時間の計測を行いました。
ウェブサイト
Quick start
https://github.com/blazegraph/database/wiki/Quick_Start
本記事の対象バージョン:2.1.6 (2020/02/04リリース)
ライセンス
オープンソース (GPL2.0ライセンス)
その他必要条件
Java 9以上
Installation¶
- Blazegraph のリポジトリから最新リリースのjarファイルをダウンロードする(https://github.com/blazegraph/database/releases)。
- 以下は wget でダウンロードする例。
wget https://github.com/blazegraph/database/releases/download/BLAZEGRAPH_2_1_6_RC/blazegraph.jar
- ダウンロードされたjarファイルを、以下のコマンドで実行する
- 実行するとWebサーバが起動するので、http://localhost:9999/ でアクセスできる
Go to http://<自分のサーバのIP>/blazegraph/のような表示も出るが、こちらでもアクセス可能
java -server -Xmx4g -jar <downloaded_dir>/blazegraph.jar
- データをロードするにはブラウザ内で、Updateタブを選択して以下のようなコマンドを入れて下の方のUpdateボタンをクリックする。
load <file:///path/to/your.ttl>
- 名前付きグラフにする場合は、以下のようにINTO GRAPH <グラフのURL>をつける
load <file:///path/to/your.ttl> INTO GRAPH <http://examples.org>
- 実行すると、一番下に小さく
Running update...と表示されるので完了するまで待つ。 - クエリを実行する場合は、Queryタブに移動してクエリを入力後、Executeボタンをクリックして実行できる。
- Web APIから実行したい場合は、http://localhost:9999/sparql に対してGETメソッドでリクエストを送ればよい。
Apache Jena Fuseki¶
Apache Jena Fuseki はApacheソフトウェア財団のコミュニティによって開発されたトリプルストアである。より正確には、Apache Jenaがトリプルストアとしての機能の核となる部分であり、Fusekiはhttpのインターフェース部分を指す。実装言語はJavaであり、単独のWebサーバとしても実行できるほか、TomcatなどのServletとしても使用することができる。オープンソースであり、ライセンスはApache ライセンスを採用している。
Apache Jena Fuseki 3.16.0に関して、弊社内Linuxサーバへのインストールを行い、インストール方法、データセットのロード方法、クエリの発行方法をdocs/md/fuseki.mdに記載しました。ロード時間に関しては、ブラウザ経由でのアップロードに関しては実験いたしましたが、他のトリプルストアに対しての実験の公平性のためコマンドラインからのロードを追って調査する予定です。
先月に弊社Linuxサーバへインストールを行ったApache Jena Fuseki 3.16.0に関して、コマンドライン経由でのデータのロードを行う方法をドキュメントに追記した上で、ロード時間の計測を行いました。
ウェブサイト
https://jena.apache.org/documentation/fuseki2/
クイックスタート
https://jena.apache.org/documentation/fuseki2/fuseki-quick-start.html
本記事の対象バージョン
3.16.0 (2020/07/09リリース)
ライセンスなど
- オープンソース(Apache 2.0 ライセンス)
必要なもの
- Java と Tomcat のインストール
Installation¶
- https://jena.apache.org/download/ からFusekiを探してダウンロード
- 例えば、wget で 3.16.0 をダウンロードする場合、以下のようにする
wget https://ftp.yz.yamagata-u.ac.jp/pub/network/apache/jena/binaries/apache-jena-fuseki-3.16.0.tar.gz
- 解凍したフォルダ内で、以下のコマンドを実行するとサーバが立ち上がるので、Webブラウザ上で
http://localhost:3030からアクセスできるようになる。
./fuseki-server
- デフォルトではlocalhost 以外からのアクセスが一部禁止されている(トップページは表示されるが、データセットのロードができない)ため、ホストの外からアクセスしたい場合は
./run/shiro.iniの以下の行をコメントアウトする。
/$/** = localhostFilter
- データセットをロードするには、ブラウザからアクセスしたあと、manage datasetsメニューのadd new datasetタブから好きな名前とDataset typeを選んでDatasetを作成する。その後、datasetメニューに移動してupload filesタブからファイルをアップロードできる。
- クエリの実行はdataset のメニューから、データセットごとに実行できる。
- Web API越しに実行する場合は、http://localhost:3030/<データセット名>/query にGETリクエストを送ると実行できる
Tomcatを使う場合
- ダウンロードしたtarファイルを解凍後、中に入っているfuseki.warをTomcatのwebapps ディレクトリにコピーする
- 例えば、Tomcatのインストールディレクトリが
/opt/tomcat/なら
cp ./fuseki.war /opt/tomcat/webapps/
- fusekiの実行に/etc/fuseki が必要らしいので、ディレクトリを作成してからtomcatのユーザに権限を付与する
sudo mkdir /etc/fuseki && sudo chgrp tomcat /etc/fuseki && sudo chown tomcat /etc/fuseki
- これで、ブラウザから http://localhost:8080/fuseki でアクセスできるようになる。
- デフォルトではlocalhost 以外からのアクセスが一部禁止されている(トップページは表示されるが、データセットのロードができない)ため、ホストの外からアクセスしたい場合は
/ets/fuseki/shiro.iniの以下の行をコメントアウトする。
/$/** = localhostFilter
コマンドラインからデータのロードを実行する場合
- tdbloaderを含んだapache-jenaのパッケージをダウンロードする
wget [https://apache.cs.utah.edu/jena/binaries/apache-jena-3.16.0.zip](https://apache.cs.utah.edu/jena/binaries/apache-jena-3.16.0.zip)
- zipファイルの展開後、./bin/tdb2.tdbloaderを使ってロードする。
- 名前付きグラフとしてロードする場合は、tdb2.tdbloader 実行時に--graph=グラフのURL のようにオプションを追加する
cd <apache-jena*.zipを解凍した場所>
mkdir tmp # いったんtmpにロード
./bin/tdb2.tdbloader --loc ./tmp <RDFデータファイルのパス>
- ロードしたデータをfusekiサーバから参照したい場合は、ブラウザ上でmanage datasets → add new dataset から好きな名前で(ここではsample_datasetとする)データセットを作る。データセットタイプはPersistent(TDB2)にする。
- 新しいデータセットを作成後、以下のコマンドでデータセットのディレクトリに先ほどtdb2.tdbloaderで作成したファイルを移動する
mv ./tmp/* <fusekiのインストール場所>/run/databases/sample_dataset/
- 一度fuseki-serverのプロセスを再起動すると、データセットがロードされた状態になる
RDF4j¶
RDF4jはEclipse財団の支援するコミュニティによって開発されたトリプルストアであり、実装言語はJavaである。3条項BSDライセンスを採用したオープンソースプロジェクトである。
RDF4j 3.3.0に関して、弊社内Linuxサーバへのインストールを行い、インストール方法、データセットのロード方法をdocs/md/fuseki.mdに記載しました。ロード時間に関しては、Fusekiと同様ブラウザ経由でのアップロードに関しては実験いたしました。
RDF4J 3.3.0に関してもコマンドライン経由でのデータのロードを試みましたが、実行時間の関係でご指定いただいた約3,000,000トリプルのRDFデータセット全体をロードすることはできなかったため、一旦約100,000トリプルのデータセットに制限してロード時間を計測させていただきました。
ウェブサイト
本記事の対象バージョン
3.3.0
ライセンス
オープンソース(Eclipse Distribution License (EDL), v1.0.)
必要なもの
Java と Tomcat のインストール
Installation¶
Webサーバとして実行する場合
RDFJ Server and Workbenchを使う
- まず、https://rdf4j.org/download/ からRDF4J 3.3.0 SDK (zip) をダウンロード
- zipファイルを解凍後、war/rdf4j-*.warをTomcatのwebappsディレクトリに以下にコピーする。
- 例えばTomcat のインストール先が/opt/tomcatなら以下のようなコマンドでコピーできる
cp rdf4j-*.war /opt/tomcat/webapps/
- ブラウザから、
http://localhost:8080/rdf4j-workbenchにアクセスするとトップページが表示される。 - Repositories -> New repository から、IDとタイトルなどを入力してリポジトリを作成する。
- リポジトリ作成後、Modify->Addからファイルをアップロードしてデータをインポートできる。
コンソールからデータをロードする場合
- zipを解凍したフォルダ内の bin/console.sh を実行するとCUIが起動する。
- まずサーバに接続
> connect http://localhost:8085/rdf4j-server
Disconnecting from default data directory
Connected to http://localhost:8085/rdf4j-server
- 次にリポジトリを作成する。最初にリポジトリのタイプ(native, memoryなど)を選択してから、リポジトリ名など必要事項を入力する。デフォルトで良い場合は何も入力しない。
> create native
Please specify values for the following variables:
Repository ID [native]:
Repository title [Native store]:
Query Iteration Cache size [10000]:
Triple indexes [spoc,posc]:
EvaluationStrategyFactory [org.eclipse.rdf4j.query.algebra.evaluation.impl.StrictEvaluationStrategyFactory]:
Repository created
- なお、すでにリポジトリを作成済みの場合は
open <repository_name>のようにすると開くことができる) - 最後に、loadコマンドでロードを行う。into以下は省略可能
> load <input_path> into <name_of_graph>
Loading data...
Data has been added to the repository (2565 ms)
Java プログラムから使用することも可能であるが、これについては実施していない。
rdfstore-js¶
rdfstore-js 0.9.17(https://github.com/antoniogarrote/rdfstore-js)に関して、弊社内Linuxサーバへのインストールを行い、インストール方法とNode.jsからの実行方法をdocs/md/rdfstore-js.mdに記載しました。
ウェブサイト
https://github.com/antoniogarrote/rdfstore-js
本記事の対象バージョン
0.9.17 (2016/09/04リリース)
ライセンス
オープンソース(MITライセンス)
Installation¶
- npmをインストール
$ sudo apt install npm
- rdfstore-js で作業するためのディレクトリを作って移動
$ mkdir ./rdfstore-js
$ cd rdfstore-js
- npm を使って必要なパッケージをインストール
$ npm install nodejs
$ npm install rdfstore
- テキストエディタなどで、以下のようなファイルを作成する。ファイル名は test.js とする。
- /path/to/dataset.ttl はロードしたいttlファイルのパスに変更する。
const rdfstore = require('rdfstore');
const fs = require('fs');
rdfstore.create(function(err, store){
const rdf = fs.createReadStream('/path/to/dataset.ttl');
store.load('text/turtle', rdf, function(s,d){
console.log(s,d);
store.execute("SELECT * WHERE { ?s ?p ?o } LIMIT 10",
function(success, results){
console.log(success, results);
});
});
});
- ファイル作成後、以下のコマンドで実行する。
- 大きめのファイルを扱う場合は、Node.jsのメモリ制限に引っかかることがあるので
--max-old-space-sizeを指定する(単位はMB)
$ node --max-old-space-size=4096 test.js
グラフデータベースの各実装¶
Neo4j¶
Neo4jはNeo4j社によって開発されたプロパティグラフを扱うグラフDBであり、クエリ言語としてCypherを利用することができる。ライセンスとしてはオープンソースのCommunity Editionに加え、有償のEnterprise版やクラウド上での利用を想定したAuraが存在する。実装はJava言語によって行われている。
Neo4j+Neosemanticsの使い方に関するドキュメントの作成
トリプルストアと異なるデータモデルであるプロパティグラフを扱うデータベースであるNeo4jに対し、RDFデータをプロパティグラフに変換しながらロードを行うプラグインであるNeosemanticsを利用する方法に関し、インデックスの張り方などを含めた調査およびドキュメントの作成を行いました。また、既存の各種トリプルストアに関するドキュメントに関しても、APIを通したクエリの実行方法や、名前付きとしてのロード方法などを追記いたしました。
Neo4jのクエリ実行時間をCUIから計測する方法に関する記載
Neo4jに対して、curlコマンドを使用してコマンドラインからクエリを実行する方法に関して、docs/md/neo4j.mdに追記させていただきました。
ウェブサイト
本記事の対象バージョン
4.1.0 Community Edition
ライセンスなど
オープンソース(Community Editionに限る。GPL v3)
必要なもの
Java のインストール
参考
Manual
https://neo4j.com/docs/operations-manual/current/installation/
Installation¶
Ubuntu 18.04の場合
参考
Manual
https://neo4j.com/docs/operations-manual/current/installation/linux/debian/
- Neo4jのパッケージリポジトリを追加する
wget -O - https://debian.neo4j.com/neotechnology.gpg.key | sudo apt-key add -
echo 'deb https://debian.neo4j.com stable latest' | sudo tee -a /etc/apt/sources.list.d/neo4j.list
sudo apt-get update
- aptでインストール
sudo apt-get install neo4j
- Neo4jをサービスとして起動する
sudo service neo4j start
- 停止する場合は以下のコマンド
sudo service neo4j stop
- localhost:7474にアクセスするとNeo4j Browserが立ち上がるはず。
- デフォルトだとユーザ名とパスワードは両方ともneo4jになっているので、これでログイン(ログイン後にパスワードの変更を求められる)
NeoSemanticsを使用する場合
参考:Tutorial https://neo4j.com/labs/neosemantics/tutorial/
参考:Configuration https://neo4j.com/docs/labs/nsmntx/current/config/
- NeoSemanticsはRDFデータを変換しつつNeo4jにインポートできるようになるNeo4jプラグイン
- まずNeoSemanticsのjarをダウンロード
wget https://github.com/neo4j-labs/neosemantics/releases/download/4.1.0.1/neosemantics-4.1.0.1.jar
- これをNeo4jのpluginsフォルダに移動
sudo mv neosemantics-4.1.0.1.jar /var/lib/neo4j/plugins/
- Neo4jの再起動
sudo service neo4j restart
- うまくいっていれば、Neo4j Browser上で
call dbms.procedures()というコマンドの実行結果の中に、n10sから始まるものが含まれているはず。 - ロードする前にconfigを初期化しておく必要があるので
n10s.graphconfig.initを呼び出す。
CALL n10s.graphconfig.init();
- また、Resourceのuriにユニーク制約を張っておく。
CREATE CONSTRAINT n10s_unique_uri ON (r:Resource)
ASSERT r.uri IS UNIQUE
- ロードする際にはプレフィックスを省略表記にするかなどをオプションで設定できる(参考:Reference)。
- 例えば、次のような形で指定可能
CALL n10s.graphconfig.init({
handleVocabUris: 'MAP'
})
- あとは
n10s.rdf.import.fetchでデータをロードする。リモートのデータをロードする場合はurlの指定をhttp:// から始める。ローカルのデータをロードする場合はfile:// から始めれば良い。以下は/home/user_name/file_name.ntをロードする場合の例。
CALL n10s.rdf.import.fetch(
'file:///home/user_name/file_name.nt',
'Turtle'
)
curlでクエリを実行する方法
実行時間を計測したい場合など、ブラウザを経由せず、curl等を用いてコマンドラインからクエリを実行したほうがよい場合がある。
- Neo4j BrowserやNeo4j Consoleを使用する場合、一応クエリごとの実行時間は表示してくれるが、これはあまり信用してはいけないらしい(以下のURLで don't rely on that exact timing と言われている)
- https://neo4j.com/developer/neo4j-browser/
- なおEnterprise版だと、
dbms.logs.query.*のようなオプションが用意されているらしい。 - コマンドラインのスクリプトから起動する場合など、curlでクエリを実行したい場合にはcurlの
-d, --dataオプションにクエリを指定して、/db/data/transaction/commitに対して実行すればよい。 - 例えば、以下のようなスクリプトを手元に用意する。名前は仮に
curl_cypher.shとする。
query=$(cat $1 | tr -d '\n')
param="{ \"statements\": [ {\"statement\": \"$query\"}]}"
curl -u neo4j:neo4j -H 'Content-type: application/json;charset=utf-8' -d "$param" http://localhost:7474/db/data/transaction/commit
- また、サンプルのクエリとして以下のようなファイルを、
sample_query.cypとして保存する。
MATCH (n) RETURN n LIMIT 10
- その後、
sh ./curl_cypher.sh sample_cypher.cypのようにして実行することで、結果がJSON形式で表示される。 - 実行時間を計測したい場合は、
time sh ./curl_cypher.sh sample_cypher.cypのようにすればよい。
Configuration¶
外部から接続したい場合
以下を行うと、任意のホストからの接続を許可することになるので、セキュリティ上の問題が起きないよう注意すること
/etc/neo4j/neo4j.confを開くと、以下のような記述があるので
##dbms.default_listen_address=0.0.0.0
コメントアウトを解除する
dbms.default_listen_address=0.0.0.0
Neo4jを再起動する
sudo service neo4j restart
Oracle Graph Server and Client (Oracle Labs PGX)¶
本記事の対象バージョン
20.4.0
ライセンスなど
OTN license
https://www.oracle.com/downloads/licenses/standard-license.html
必要なもの
Java のインストール
Installation¶
Ubuntu 18.04の場合
- 2021/1 現在、公式に配布されているのは rpm パッケージのみなので、Ubuntuにインストールするためにまず deb パッケージ に変換してからインストールする。
- 参考:[https://phoenixnap.com/kb/install-rpm-packages-on-ubuntu]
sudo add-apt-repository universe
sudo apt-get update
sudo apt install alien
sudo alien --scripts oracle-graph-20.4.0.x86_64.rpm # --scriptsオプションをつけないとインストール時に権限周りで失敗する
sudo dpkg -i oracle-graph_20.4.0-1_amd64.deb
- インストール後、標準では
/opt/oracle/graph/にインストールされる。とりあえずコマンドライン上で試すのであれば、bin/opg-jshellが試しやすい
sudo /opt/oracle/graph/bin/opg-jshell
sudo systemctl start pgxのようにしてサーバプロセスとして起動することもできるが、その場合/etc/oracle/graph/server.confや/etc/oracle/graph/pgx.confにセキュリティ関係の設定を適切に編集する必要があるほか、Oracle DB などを IdentityProvider として使用する必要があるため割愛。opg-jshell内でPGQLを実行する場合は、例えば以下のようにする
opg-jshell> var G = session.readGraphWithProperties("/tmp/example.pgx.json") // 読み込みたいpgx 用の json を指定
G ==> PgxGraph[name=sample.pgx,N=554,E=1528,created=1612683135450]
opg-jshell> G.queryPgql("SELECT * MATCH (a)-[]->(b) LIMIT 10").print() // 任意のリレーションを最大10個取得して表示
また、クエリの実行時間計測は以下のコードで行える。なお、query変数には事前にクエリの文字列を代入しておくものとする。
var start = System.currentTimeMillis(); G.queryPgql(query);
var end = System.currentTimeMillis(); end - start
ArangoDB¶
ArangoDB は ArangoDB GmbHが開発するオープンソースのマルチモデルDBであり、キーバリュー型のデータ、ドキュメントデータ、グラフデータを同じDBエンジン上で扱うことを可能とする。クエリ言語はAQL(ArangoDB Query Languade)と呼ばれ、異なる3種のデータモデルに対し、共通の言語でクエリを発行できるようになっている。ライセンスはオープンソースのCommunityに加え、並列実行などの機能を追加したEnterprise、フルマネージド版のOasisが存在している。実装言語としてはC++が用いられている。
データセット¶
パフォーマンステスト用のデータセットとして、NCBI taxonomy dataをftp://ftp.ncbi.nlm.nih.gov/pub/taxonomy/taxdump.tar.gz を用いた。
https://graphdb.dbcls.jp/benchmark/taxonomy_2019-05-01.ttl (1.2GB, 30M triples)
https://graphdb.dbcls.jp/benchmark/taxonomy_2019-05-01.nt (3.8GB, 30M triples)
https://graphdb.dbcls.jp/benchmark/taxonomy_2019-05-01.pg (935MB, 15M nodes, 20M edges)
https://graphdb.dbcls.jp/benchmark/taxon_40674.nt (907KB, 166894 triples)
また、Oracle Labs PGXに同等のデータをロードするため、ftp://ftp.ncbi.nlm.nih.gov/pub/taxonomy/taxdump.tar.gzを変換するRubyスクリプトtaxdump2pg.rbを作成した。本スクリプトは、https://github.com/dbcls/rdfsummit/blob/master/taxdump2owl/taxdump2owl.rb を元に作成しており、PG tools (https://pg-format.readthedocs.io/en/latest/) で扱うことのできるpgフォーマットでtaxonomyデータを作成する。さらにこのpgフォーマットから。pg2pgxコマンドを使用することで、Oracle Labs PGXにロード可能なデータ形式への変換を行った。
クエリ¶
SPARQLクエリ¶
count_taxa
PREFIX taxon: <http://ddbj.nig.ac.jp/ontologies/taxonomy/>
SELECT (COUNT(?taxid) AS ?count)
FROM <http://ddbj.nig.ac.jp/ontologies/taxonomy/>
WHERE {
?taxid a taxon:Taxon .
}
count_classes
SELECT (COUNT(?instance) AS ?count) ?class
FROM <http://ddbj.nig.ac.jp/ontologies/taxonomy/>
WHERE {
?instance a ?class .
}
GROUP BY ?class
ORDER BY DESC(?count)
count_from_graph
SELECT (COUNT(*) AS ?count)
FROM <http://ddbj.nig.ac.jp/ontologies/taxonomy/>
WHERE {
?s ?p ?o
}
count_in_graph
SELECT (COUNT(*) AS ?count)
WHERE {
GRAPH <http://ddbj.nig.ac.jp/ontologies/taxonomy/> {
?s ?p ?o
}
}
count_in_taxon
PREFIX taxid: <http://identifiers.org/taxonomy/>
SELECT (COUNT(DISTINCT ?taxid) AS ?count)
FROM <http://ddbj.nig.ac.jp/ontologies/taxonomy/>
WHERE {
?taxid rdfs:subClassOf* taxid:9443 .
}
count_in_taxon_label
PREFIX rdfs: <http://www.w3.org/2000/01/rdf-schema#>
SELECT (COUNT(DISTINCT ?taxid) AS ?count) ?taxon
FROM <http://ddbj.nig.ac.jp/ontologies/taxonomy/>
WHERE {
?taxid rdfs:subClassOf* ?taxon .
?taxon rdfs:label "Primates" .
}
GROUP BY ?taxon
get_hierarchy
PREFIX rdfs: <http://www.w3.org/2000/01/rdf-schema#>
PREFIX taxid: <http://identifiers.org/taxonomy/>
PREFIX taxon: <http://ddbj.nig.ac.jp/ontologies/taxonomy/>
SELECT ?order ?order_name ?family ?family_name ?species ?name
FROM <http://ddbj.nig.ac.jp/ontologies/taxonomy/>
WHERE {
?species taxon:rank taxon:Species ;
rdfs:label ?name ;
rdfs:subClassOf+ taxid:40674 ;
rdfs:subClassOf+ ?family ;
rdfs:subClassOf+ ?order .
?family taxon:rank taxon:Family ;
rdfs:label ?family_name .
?order taxon:rank taxon:Order ;
rdfs:label ?order_name .
}
ORDER BY ?order_name ?family_name ?name
filter_regex
PREFIX rdfs: <http://www.w3.org/2000/01/rdf-schema#>
SELECT *
FROM <http://ddbj.nig.ac.jp/ontologies/taxonomy/>
WHERE {
?taxid rdfs:label ?label .
FILTER regex(?label, "Homo ")
}
common_ancestor
PREFIX rdfs: <http://www.w3.org/2000/01/rdf-schema#>
PREFIX taxid: <http://identifiers.org/taxonomy/>
SELECT ?ancestor ?p ?o
FROM <http://ddbj.nig.ac.jp/ontologies/taxonomy/>
WHERE {
?ancestor ?p ?o .
?tax1 rdfs:subClassOf ?ancestor .
?tax2 rdfs:subClassOf ?ancestor .
taxid:9606 rdfs:subClassOf* ?tax1 .
taxid:511145 rdfs:subClassOf* ?tax2 .
FILTER(?tax1 != ?tax2)
}
taxon_info
PREFIX taxid: <http://identifiers.org/taxonomy/>
SELECT *
FROM <http://ddbj.nig.ac.jp/ontologies/taxonomy/>
WHERE {
taxid:9606 ?p ?o .
}
taxon_info_ordered
PREFIX taxid: <http://identifiers.org/taxonomy/>
SELECT ?p ?o
FROM <http://ddbj.nig.ac.jp/ontologies/taxonomy/>
WHERE {
taxid:9606 ?p ?o .
}
ORDER BY ?p ?o
Cypherクエリ¶
count_taxa
MATCH (n:Taxon) RETURN COUNT(n)
count_classes
MATCH (n:Resource) RETURN DISTINCT count(labels(n)), labels(n)
count_from_graph および count_in_graph (Neo4j + Neosemanticsでは名前付きグラフとしてロードされないため、今回は同一クエリとして計測)
MATCH (n)-[r]->() RETURN COUNT(r)
count_in_taxon
MATCH (tax:Resource)-[r:subClassOf*..]->(n2:Resource
{uri:'http://identifiers.org/taxonomy/9443'})
RETURN DISTINCT COUNT(tax)
count_in_taxon_label
MATCH (taxid:Resource)-[rdfs:subClassOf*..]->(:Resource {label:'Primates'})
RETURN COUNT(DISTINCT(taxid))
get_hierarchy
MATCH
(species:Resource)-[:subClassOf*1..]->(:Resource
{uri:'http://identifiers.org/taxonomy/40674'}),
(species:Resource)-[:rank]->(taxon:Resource
{uri:'http://ddbj.nig.ac.jp/ontologies/taxonomy/Species'})
MATCH
(species)-[:subClassOf*1..]->(family:Resource)-[:rank]->
(:Resource {uri:'http://ddbj.nig.ac.jp/ontologies/taxonomy/Family'})
MATCH
(species)-[:subClassOf*1..]->(order:Resource)-[:rank]->(:Resource
{uri:'http://ddbj.nig.ac.jp/ontologies/taxonomy/Order'})
RETURN
order.uri, order.label, family.uri, family.label, species.uri, species.label
filter_regex
MATCH (taxid:Resource)
WHERE taxid.label =~ '.*Homo .*'
RETURN taxid
common_ancestor
MATCH (tax9606:Resource {uri:'http://identifiers.org/taxonomy/9606'}),
(tax9606)-[:subClassOf*1..]->(ancestor:Resource)
MATCH
(tax511145:Resource {uri:'http://identifiers.org/taxonomy/511145'}),
(ancestor)<-[:subClassOf*1..]-(tax511145)
MATCH
(ancestor:Resource)-[p]->(o)
RETURN ancestor, p, o
taxon_info
MATCH (n:Resource
{uri:'http://identifiers.org/taxonomy/9606'})-[r]->(n2:Resource)
RETURN r, n2
taxon_info_ordered
MATCH (n:Resource
{uri:'http://identifiers.org/taxonomy/9606'})-[r]->(n2:Resource)
RETURN r, n2 ORDER BY r.uri, n2.uri
PGQLクエリ¶
Oracle Labs PGXで性能測定を行うために記述したクエリ群を以下に示す。
common_ancestor.pgql
SELECT * MATCH (tax9606)-/:subClassOf+/->(ancestor)<-/:subClassOf+/-(tax511145) WHERE id(tax9606) = '9606' AND id(tax511145) = '511145'
count_classes.pgql
SELECT DISTINCT COUNT(n.label_), n.label_ MATCH (n) GROUP BY n.label_
count_in_graph.pgql
SELECT COUNT(r) MATCH (n)-[r]->()
count_in_taxon_label.pgql
SELECT COUNT(DISTINCT(taxid)) MATCH (taxid)-/:subClassOf+/->(r) WHERE r.label = 'Primates'
count_in_taxon.pgql
SELECT COUNT(tax) MATCH (tax)-/:subClassOf*/->(n2) WHERE id(n2) = '9443'
count_taxa.pgql
SELECT COUNT(n) MATCH (n) WHERE n.label_ = 'Taxon'
filter_regex.pgql
SELECT id(n) MATCH (n) WHERE JAVA_REGEXP_LIKE( n.label, '.*Homo .*' )
get_hierarchy.pgql
SELECT order.label, id(family), family.label, id(species), species.label MATCH (species)-/:subClassOf+/->(ancestor), (species)-/:subClassOf+/->(family), (species)-/:subClassOf+/->(order) WHERE species.rank = 'Species' AND id(ancestor) = '40674' AND family.rank = 'Family' AND order.rank = 'Order'
taxon_info_ordered.pgql
SELECT * MATCH (n)-[r]->(n2) WHERE id(n) = '9606' ORDER BY id(r), id(n2)
taxon_info.pgql
SELECT * MATCH (n)-[r]->(n2) WHERE id(n) = '9606'
計測結果¶
taxonomy_2019-05-01.nt での計測結果¶
各種データベースに taxonomy_2019-05-01.nt データを用いてロード速度を計測したところ、以下の通りになった。なお、トリプルストアとの比較のために Neo4j+Neosemantics 、およびOracle Labs PGXを用いたものに関しても計測を行った。当該データに関し、表や図の中では単に「Neo4j」「Oracle PGX」と表記する(Oracle PGXに関しては、クエリの実行時間のみ調査を行った)。
| トリプルストア | ロード速度 (M triples/min) | |---|---:| | Virtuoso | 5.812 | | Blazegraph | 3.299 | | Stardog | 1.885 | | GraphDB | 1.102 | | Fuseki | 3.386 | | AllegroGraph | 3.999 | | RDF4J | 2.333 | | Neo4j | 1.863 |
さらに各種データベースに関して、クエリセットの実行時間の調査を行った。調査対象は上記11クエリになっており、各クエリに関して3回ずつ実行した上で、平均を調べた。トリプルストア間の実行時間の比較を下図に示す。なお、トリプルストアによってはクエリの結果がキャッシュされる場合があるためか、初回と2回目以降の時間が大きく変わるものがあったため、初回のみの時間と平均の時間の両方を記載する。縦軸の単位はミリ秒である。
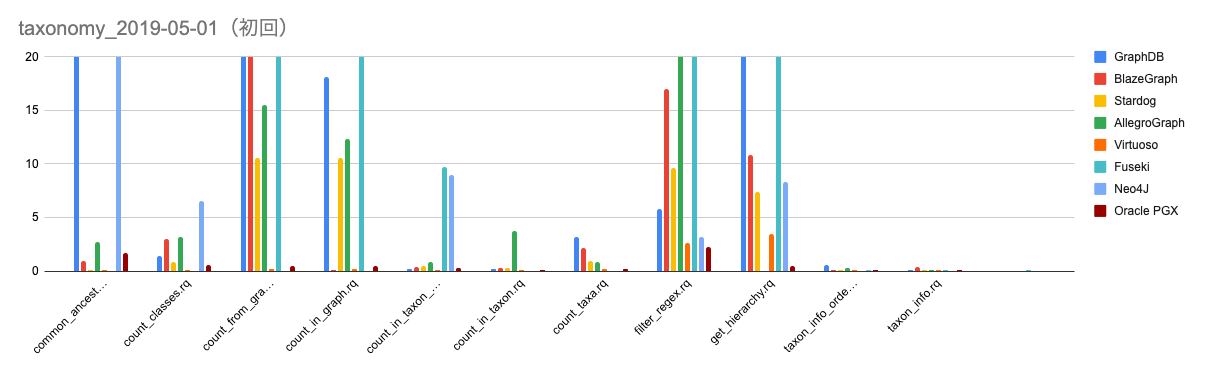 ../img/taxonomy_2019-05-01_1st.png
../img/taxonomy_2019-05-01_1st.png
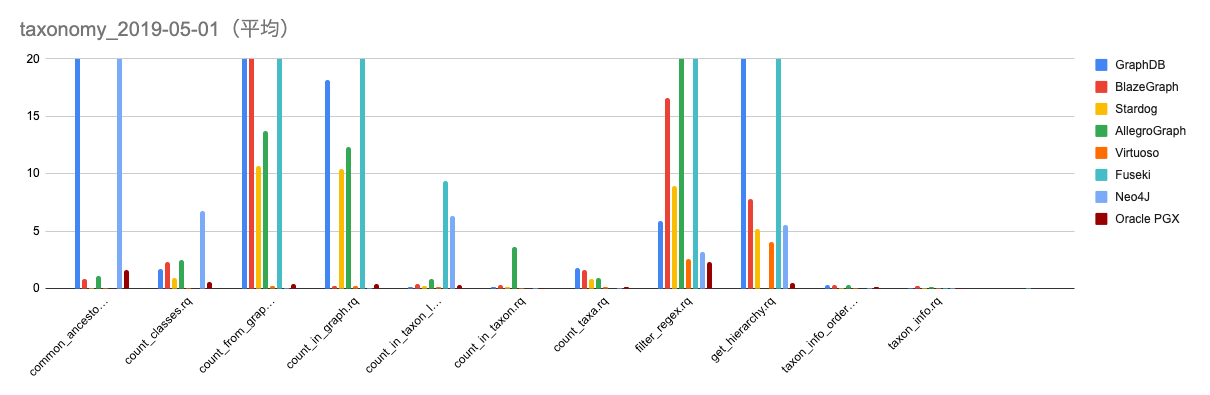 ../img/taxonomy_2019-05-01_mean.png
../img/taxonomy_2019-05-01_mean.png
taxon_40674.ntを用いた計測結果¶
小規模データとしてtaxon_40674.ntを利用した場合の各種トリプルストアのロード速度とクエリの実行時間の調査を行った。計測は3回行い、初回のみの値と平均の値をグラフとした。縦軸の単位は秒になっている。
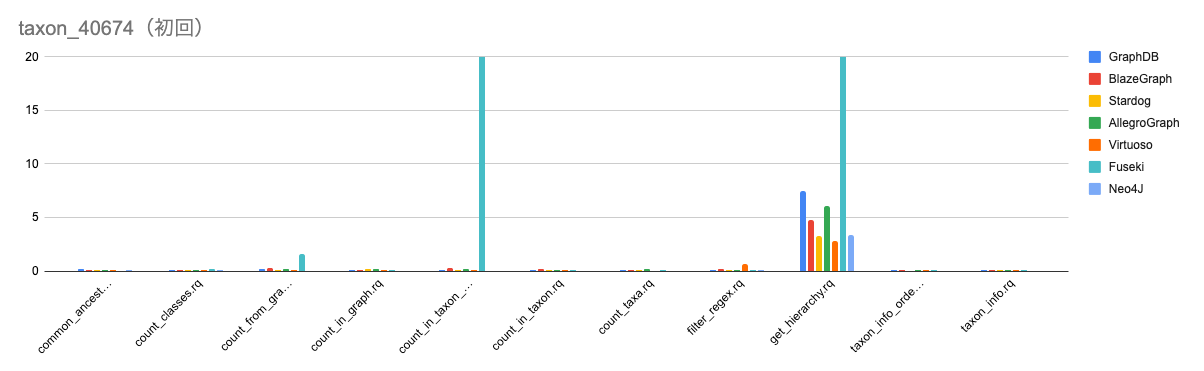 ../img/taxon_40674_1st.png
../img/taxon_40674_1st.png
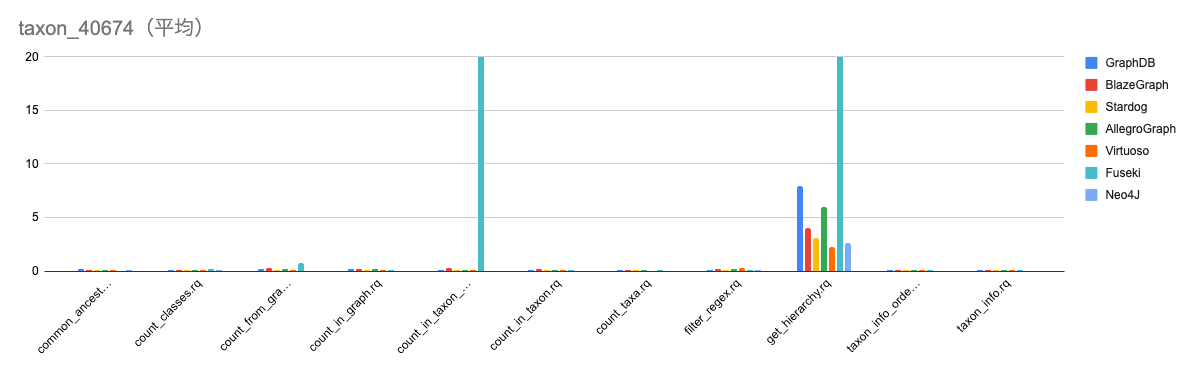 ../img/taxon_40674_mean.png
../img/taxon_40674_mean.png
考察と課題¶
今回は、特定のLinuxマシンの上で、パフォーマンスの測定を行った。しかし、再現性を確保する観点から、任意のマシンの上で同じ実験を遂行することができることが望ましい。そこで、各データベースエンジンのインストールプロセスをDocker化したうえで、パフォーマンス測定まで行うことができるようにする。
また、今回は特定のデータセットのみを用いて測定を行った。一般的なRDFに適用できる情報ではあるが、どこまでデータサイズに関して、スケールするかについては未検討である。そこで、特にパフォーマンスの良かったエンジンについては、大メモリマシンで、データセットをスケールさせてパフォーマンスを調査することが必要になる。
各種トリプルストアおよびプロパティグラフDBのDocker化¶
Docker環境に対して、トリプルストアやプロパティグラフDBを容易にデプロイできることを目的とし、以下のソフトウェアのDockerfile、および必要なファイル群を作成の上、graphdbsリポジトリのdocker_filesディレクトリに配備しました。
- Virtuoso 7.2.5.2
- Neo4j 4.2.3 Community Edition
- GraphDB 9.6.0 Free Edition
- Blazegraph 2.1.5